Building the Amplidex; A GraphQL Powered Pokedex

Hello there! Welcome to the world of Amplication. My name is Michael; people refer to me as Amplication's Developer Advocate.
Today, I want to show you how to build a backend GraphQL API using Amplication and some other valuable bits, such as how to seed a database using Prisma and how to scrape data off the internet. Consider this a weekend project to build something fun and exciting using open-source technologies and best practices with a straightforward-to-follow guide.
The web is inhabited far and wide by backend servers. For some people, they like to communicate with a backend using GraphQL. Others prefer traditional REST API requests. As for myself, I help developers build these backends that power the web. Your very own Amplication legend is about to unfold! A world of dreams and adventures with Amplication awaits. Let's go!
All kidding aside, I woke up on February 6th to see that Mewtwo was trending on Twitter. So naturally, as a genwunner, I felt compelled to learn more about why Mewtwo was trending. I discovered that February 6th is Mewtwo's birthday! And that inspired this entire post.
Today is mewtwo's birthday! pic.twitter.com/J9qO9SGlGS
— OnThisDayInGaming (@OnThisDayGaming) February 6, 2017
With all that said, I have a request for you. Below is a crash course on building a Pokedex GraphQL API using Amplication and data scraped from Bulbapedia. It'll be a high-tech encyclopedia! So read on, and let's create something fun together.
Building the Pokedex, a Pokemon Encyclopedia
Before we can even begin to log all 1008 Pokemon, we first need to have someplace to log them. A Pokedex, so to speak. But we live in a modern world where everything is connected to the internet, so we're going to create a Pokedex that can serve many Pokemon trainers worldwide. But, of course, this requires a backend server, and to build our backend server, we'll need Amplication. So, head to app.amplication.com and sign in to get started.
Add a new project to your workspace; I'm calling mine Amplidex. Once the project is created, add a service resource and use the default settings.
This service will be the backbone of our Pokedex, as it'll be serving all of the data on the different monsters, typings, and generations; it's not a complex Pokedex, but it's more than enough to showcase what's possible. With that in mind, we'll create three entities in this service:
- Generation
- Monster
- Typing
For both the Generation and Typing entities, add a field and call it Name. The Name field will be a single line text field; additionally, it should be a unique field, a required field, and searchable. At some point, we'll add a field called Monsters to these two entities, allowing us to search for Pokemon based on their generation or typings. This relation will be created from inside the Monster entity.
So let's move to the Monster entity and add the following fields, with the configurations shown in the sub-bullet points:
- Name
- Unique Field
- Required Field
- Searchable
- Single Line Text
- Dex Number
- Unique Field
- Required Field
- Searchable
- Whole Number
- Biology
- Required Field
- Searchable
- Multi Line Text
- URL
- Unique Field
- Required Field
- Searchable
- Single Line Text
- Image
- Required Field
- Searchable
- Single Line Text
This is all helpful information for a Pokedex. Look through the different configuration options. You'll see how much control Amplication provides for the data you want to store and how easy it is to validate and protect data being written to your backend and database.
In the last two fields, we'll add our Generation and Typing. Starting with Generation, Amplication looks through your entities and sees that you have an entity called Generation. Amplication will suggest that a Monster's Generation field should be related to the Generation entity, which is precisely what we want. One monster can only be related to one generation, so select that option when creating the relationship. Also, remember to set the field to be required and searchable.
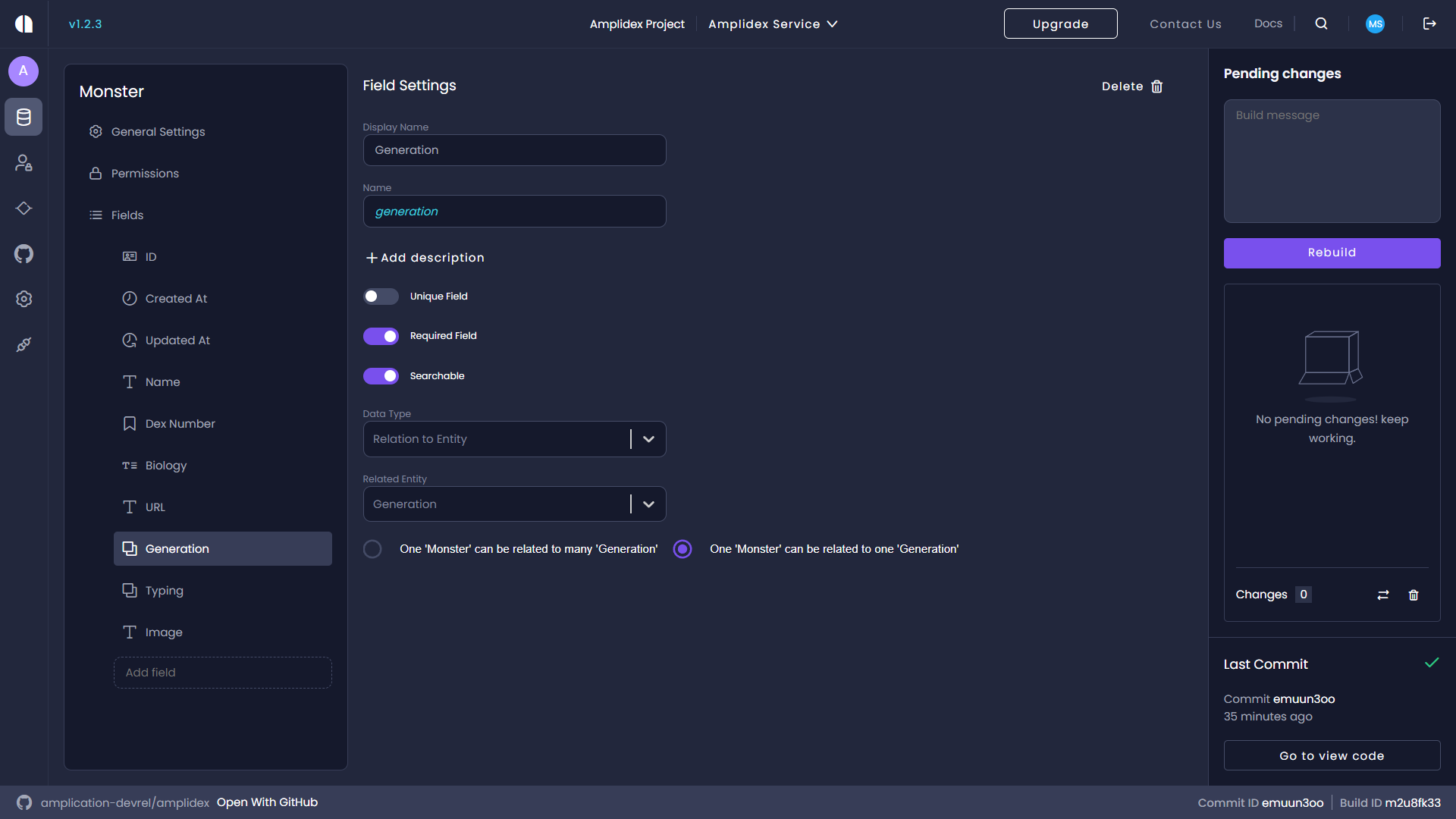
Now create your Typing field, and like with the Generation field above, Amplication will attempt to build a relation between the field and the entity. In this case, though, a Pokemon can have multiple typings, so be sure to select one monster can be related to many typings. Again remember to set the field to be required and searchable.
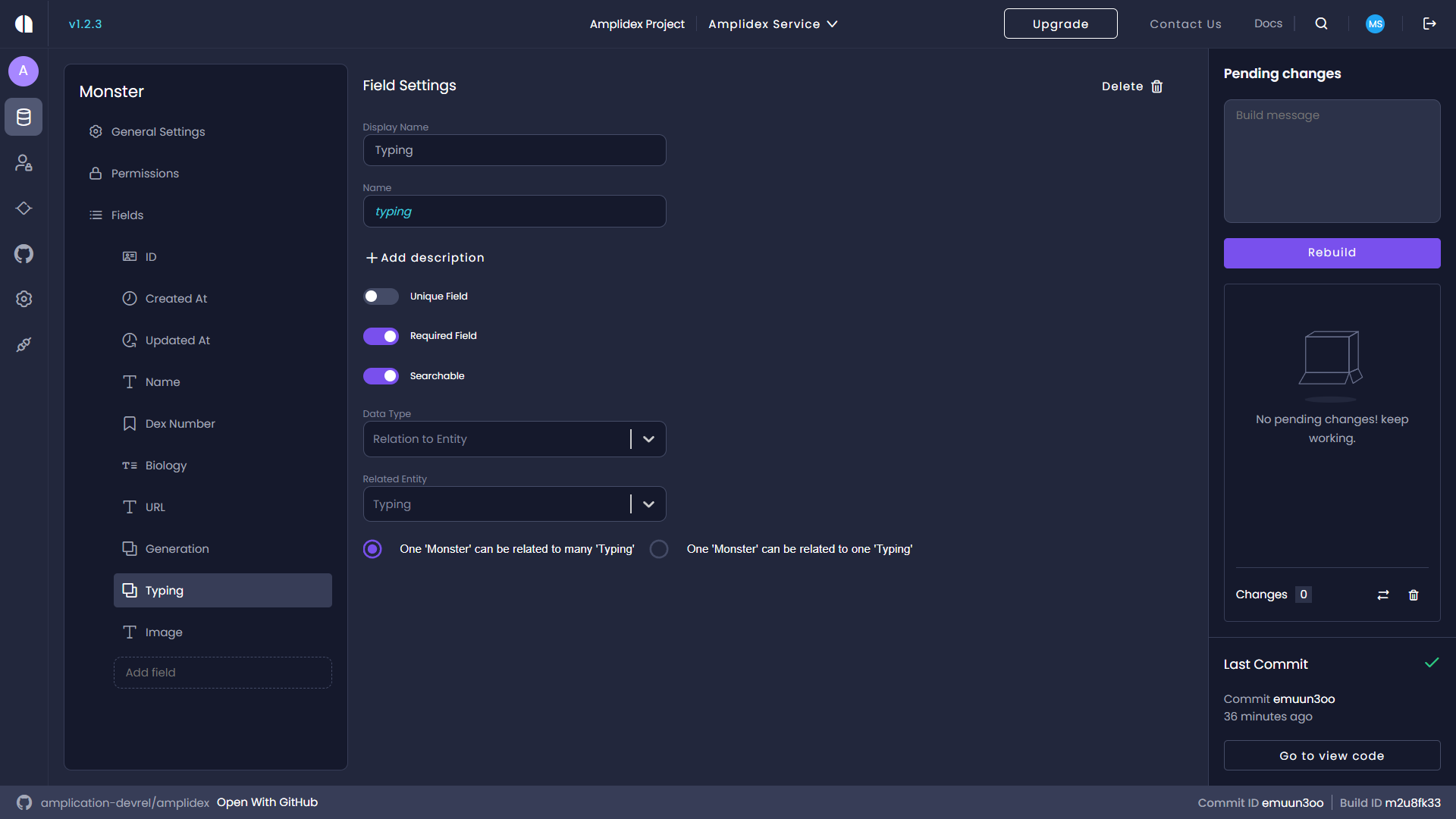
For this Pokedex to work for everyone to use, we will need to make one change to our Amplication service, which is to make some of the entities' actions public. By default, all requests, mutations, and queries to an Amplication-generated backend require a user to be authenticated. For this backend, we want to allow any developer to be able to search it. Therefore, we want to set the View and Search actions to Public for our newly created entities, Monster, Generation, and Typing. Click into an entity and select Permissions on the left-hand side; you'll be greeted with a robust UI for protecting your entities. Make sure to set the View and Search actions to Public here. For a deeper dive into how to use entity permissions, check out this article on the Amplication docs site.
With the Pokedex backend created, you'll want to run the code locally to continue this guide. This requires syncing code to GitHub and then cloning it locally. Assuming you're comfortable with git commands, such as git clone, check out this article on the Amplication docs site to learn how to sync your code to GitHub.
Gotta Scrape 'Em All
Nicely done, trainer; you now have a Pokedex, but you still need to see all 1008 Pokemon! That's ok. Rather than being 10 years old for the next 25 years, there's an easier way to get all the data we need. Bulbapedia has all the data we need, it may be challenging to scrape, but here I'll walk you through all the steps to get the data we need.
If you still need to clone the Amplication code from GitHub, now is the time to do it. Once you've done that, open the server folder in your IDE (as that's where we'll be doing all of our work), and create a new folder called data. Then, inside the data folder, create a file called scraper.ts. Our scraper will depend on a few libraries not installed on the Amplication generated server, so run the following commands to install all existing dependencies and then add the few remaining dependencies we need.
npm i
npm i -D @types/node cheerio isomorphic-unfetchIn the scraper.ts file, copy the following code, and we'll work through the rest of the scraper.
import { load } from "cheerio";
import { writeFileSync } from "fs";
import fetch from "isomorphic-unfetch";
import { URL } from "node:url";
(async () => {
const stop = "https://bulbapedia.bulbagarden.net/wiki/Bulbasaur_(Pok%C3%A9mon)";
let url = stop;
const pokedex: any[] = [];
})();Take a look at the stop variable. You should see that it's a URL; if you click on it, you'll be sent to the Bulbasaur entry in Bulbapedia. Bulbasaur is the first Pokemon in the National Pokedex, so it'll be the first Pokemon we scrape. It'll also be how we know when we get to the end of the National Dex. The way our scraper will work is as we scrape a Pokemon, we'll also scrape the URL of the next Pokemon in the Dex and then scrape that one. When we get to the last Pokemon, rather than having no next Pokemon, Bulbapedia loops back to the first Pokemon. This is how we know we've reached the end.
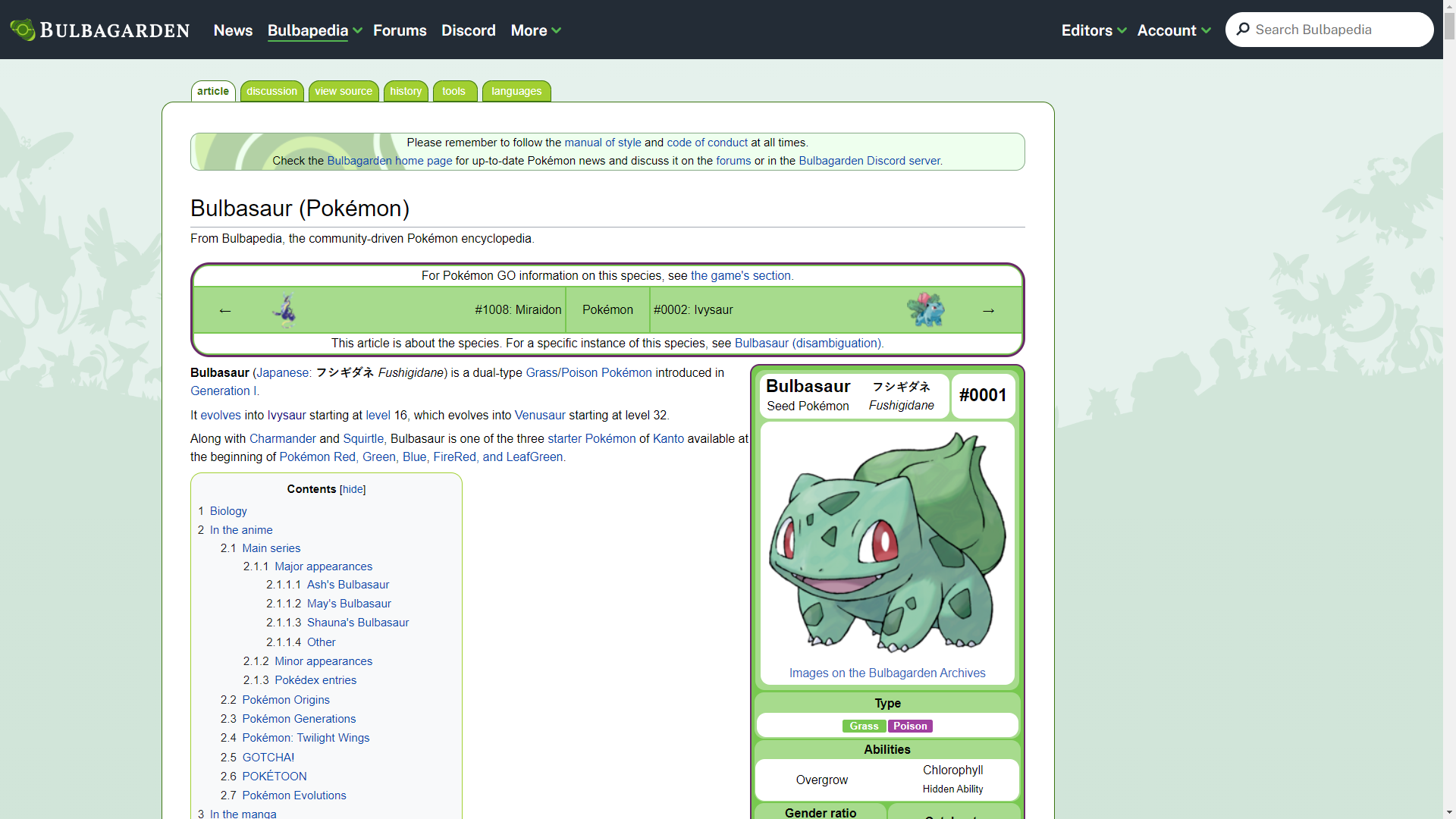
So the url variable will keep updating as we scrape Bulbapedia in a do...while loop, and once the value of url becomes the stop value again, we stop the loop.
Calculating a Pokemon's Generation
One piece of information that Bulbapedia doesn't make easy to extract is what generation a Pokemon first appeared in. It is easy to figure out, though, as the Pokemon's index in the National Dex allows us to derive the generation it belongs to. Copy the following function into scraper.ts to determine to which generation a Pokemon belongs.
/**
* Returns what generation a Pokemon belongs to based on their Pokedex number.
* @param num Pokedex number
* @returns number
*/
const calculateGeneration = (num: number): number => {
if (num <= 151) return 1;
if (num <= 251) return 2;
if (num <= 386) return 3;
if (num <= 493) return 4;
if (num <= 649) return 5;
if (num <= 721) return 6;
if (num <= 809) return 7;
if (num <= 905) return 8;
if (num <= 1008) return 9;
return 0;
}Creating the Scraping Loop
Now we begin the scraping. As mentioned above, we'll execute a do...while loop to figure this out. Add the following code to the scraper.
do {
const response = await fetch(url);
const body = await response.text();
const $ = load(body);
} while (url !== stop);
The first step of the loop is making an HTTP GET request to the Bulbapedia entry of a Pokemon, starting with Bulbasaur. We get the response, convert it into plain text, and load it into cheerio. Cheerio is an implementation of core jQuery designed to run in the server; it's also what we'll use to rip data of the Pokemon for our Pokedex.
Scraping the Data
The first field we'll want to get is a Pokemon's name. Thankfully, all entries in Bulbapedia have an H1 heading with an id of firstHeading, which makes it easy to pull. The only issue is that all Pokemon entries are suffixed with " (Pokémon)", so we'll want to remove that. So, add the following code to the do...while loop to scrape a Pokemon's name.
// Grab name of Pokemon and remove "(Pokémon)" from string
const name = $("#firstHeading").text().replace(" (Pokémon)", "");The following field we need is the Dex number. This information requires some work to rip, but only a little more. We want to store the Dex number as an actual number. However, Bulbapedia provides the number as a string prefixed with an octothorpe (#). Copy the following code to the do...while loop to scrape a Pokemon's Dex number.
// Get Pokedex number of Pokemon and convert into a number
const dexNumber = parseInt(
$('big > a[title="List of Pokémon by National Pokédex number"] > span')
.text()
.replace("#", "")
);Getting the image URL of a Pokemon is somewhat straightforward, as thankfully, all of them are wrapped in an A tag with a href that starts with /wiki/File:, so we'll use that in our query selector to get the IMG's src attribute value. Since it doesn't have the protocol in the URL, we'll manually add the HTTPS.
// Get Pokemon's picture
const image = 'https:' + $('a[href*="/wiki/File:"] > img').attr("src");Getting a Pokemon's biology information is a little more complex. It's not neatly wrapped in an element from which we can get the text. So we have to find the heading element of the Biology section of the page instead and then iterate over its sibling elements until we reach the next heading. We'll get the text content of every P tag after the Biology heading until we reach the next heading, which symbolizes a new section.
// Rip Pokemon's biology
let biologyStart = $("h2 > #Biology").parent().next();
const biology: string[] = [];
while (!biologyStart.is("h2")) {
biology.push(biologyStart.text());
biologyStart = biologyStart.next();
}The dirtiest part of this code is getting the typings of a Pokemon. There is no easy way to do it. It gets more complex because some Pokemon have regional forms, mega-evolutions, terastallized forms, etc., all of which may have different typing than their base form. Thankfully I'm not an actual Pokemon professor, just a Developer Advocate. So we'll get all the types, regardless of forms, capitalize them, and eliminate duplicates. (Bulbapedia does some weird things with its typings, and you can get a lot of "Unknown" types, just go with the code below and trust it works.)
// Get Pokemon's typings and clean data
const types = $(
"#mw-content-text > div > table > tbody > tr > td > table > tbody > tr > td > table > tbody > tr > td > a[title*=type] b"
).toArray();
const typing = Array.from(
new Set(
types
.map((e) => ((e.children[0] as any).data as string).toUpperCase())
.filter((e) => e !== "UNKNOWN")
)
);Now we're ready to create our Pokemon object and put it into our Pokedex array. We'll also need to calculate the generation the Pokemon belongs to, and then, join all of the biology paragraphs together. The following code does all of that for us.
// Create Pokemon object and push into Pokedex
const pokemon = {
biology: biology.join("").trim(),
dexNumber,
generation: calculateGeneration(dexNumber),
image,
name,
typing,
url,
};
pokedex.push(pokemon);For the loop to work, we need to make sure we get the URL of the next Pokemon. The final bit of code inside the do...while loop will get that URL and assign it to the url variable.
// Set next Pokemon's URL
url = new URL(
$(
'#mw-content-text > div > table > tbody > tr > td > table > tbody > tr > td[style="text-align: left"] > a'
).attr("href") as string,
"https://bulbapedia.bulbagarden.net"
).toString();Saving All Pokemon Data
The scraper will loop through all the Pokemon on Bulbapedia until it reaches Miraidon. Once on Miraidon, the next Pokemon will be Bulbasaur, and the while condition will be met, breaking the do...while loop. Once we've scraped all the Pokemon, we'll need to save that data to seed into our Pokedex backend. Add the following line after the do...while loop.
writeFileSync("./data/pokedex.json", JSON.stringify(pokedex, null, "\t"));With everything set, let's scrape the data. Open up a terminal window and navigate to the root of the server folder. Run the command ts-node ./data/scraper.ts and wait. After a minute or so, you'll have a file called pokedex.json in the data folder with details on every Pokemon.
View the full scraper.ts file here on GitHub.
Creating a Custom Seed
When running an Amplication project locally, you must take a few steps, including configuring and seeding your database. We have all the data of our Pokemon, so we'll want to populate that data into the backend. By default, Amplication created an admin user but has a file that allows us to seed our database with whatever information we want. To get started, we need to generate the Prisma client, which the Node.js app uses to communicate with the database. Run the following command.
npm run prisma:generateNow, open the file scripts/customSeed.ts in the server folder. Delete everything in the file and copy in the following.
import { Generation, PrismaClient, Typing } from "@prisma/client";
import pokedex from "../data/pokedex.json";
export async function customSeed() {
const client = new PrismaClient();
client.$disconnect();
}Seeding Generation & Typing Data
We'll start by seeding the database with all the generation information of our Pokemon. This works by looping through all the Pokemon in the pokedex.json that the scraper creates, taking the generation field and prefixing it with the text "Generation ". This will lead to many duplicates, so we'll put it all into a Set to filter out duplicates and then convert it back into an Array. We'll then loop through the de-duped generations and upsert them in our database. We upsert because if the generation already exists, we can update the field and get all the information from our database instead of creating a new one. We want to get the information of the generation from our database in order to map a Pokemon to a generation later on. Copy the following data into the customSeed function after the client is initialized and before client.$disconnect() is called.
// Load Pokemon Generations
const generationsInserted: Generation[] = [];
const generations = Array.from(
new Set(
pokedex.reduce(
(acc: string[], cur) => [...acc, `Generation ${cur.generation}`],
[]
)
)
);
for (const generation of generations) {
const result = await client.generation.upsert({
where: { name: generation },
update: { name: generation },
create: { name: generation },
});
generationsInserted.push(result);
}Seeding the typing data of our Pokemon follows an almost identical process to the generation data. First, we'll take all the Pokemon and loop over them. We'll take each Pokemon's typings and flatten the data, so all the types of Pokemon are inside of one Array. Then, to de-dupe the typings, we'll pass the Array into a Set and convert it back into an Array. We'll also upsert the typing data, not to introduce duplicate data into the database, and to get the typing data from the database to map each Pokemon to its typing. Copy into the customSeed function the following code.
// Load Pokemon Typings
const typingsInserted: Typing[] = [];
const typings = Array.from(
new Set(pokedex.reduce((acc: string[], cur) => [...acc, ...cur.typing], []))
);
for (const typing of typings) {
const result = await client.typing.upsert({
where: { name: typing },
update: { name: typing },
create: { name: typing },
});
typingsInserted.push(result);
}Functions to Get Generations and Typings
With the typing and generation data securely in the database, we also have the necessary data to connect our Pokemon to them. As we upserted both bits of data, we also pushed the results into two different Arrays. To figure out the unique identifiers (UID) for any generation or typing, we'll create two functions that will loop through the data from the database and return the UID of the corresponding generation or type.
const getGeneration = (gen: number): string => {
for (const generation of generationsInserted) {
if (generation.name === `Generation ${gen}`) return generation.id;
}
return "";
};
const getTyping = (type: string): string => {
for (const typing of typingsInserted) {
if (typing.name === type) return typing.id;
}
return "";
};Now, when we add our Pokemon data to the database, we can also link them to the appropriate generation and typings by calling on these two functions.
Seeding Pokemon Data
Everything is in place, and now we must add our Pokemon data to the database. The process is as simple as a for loop, but now would be a good point to explain how we've been using the upsert function for our entities. Copy the code below and then read on for an explanation.
for (const pokemon of pokedex) {
await client.monster.upsert({
where: { name: pokemon.name },
update: { name: pokemon.name },
create: {
biology: pokemon.biology,
dexNumber: pokemon.dexNumber,
generation: {
connect: {
id: getGeneration(pokemon.generation),
},
},
image: pokemon.image,
name: pokemon.name,
url: pokemon.url,
typing: {
connect: pokemon.typing.map((t: string) => ({
id: getTyping(t),
})),
},
},
});
}The upsert method takes in an argument of an object, and the object has three fields; where, update, and create.
The where property is how we know which object in our Monsters entity to upsert. We don't have the UID of a Pokemon, but we do have its name, which was set to be a unique field when we created the field, as mentioned earlier. So when upserting, we tell Prisma to only upsert a Pokemon with that specific name, and we know there will only be one entry with that name since the name has been marked as unique.
The update field is only run when the Pokemon declared in the where field is found. While we hope to seed the database only once, in case this function is rerun, the upsert function allows us to safely execute the code without throwing errors. So, if the Pokemon is found, we'll have to update the data, and to keep things from getting messy, we only reassign the name to the same name.
Finally, there is the create field. When a Pokemon isn't found with the where field, we'll want to insert a new Pokemon into the database. While most of the fields of the Pokemon data from the pokedex.json are mapped to the same name in the create field's object, the generation and typing fields are a bit different. To link typing to the Typing entity and generation to the Generation entity, we use connect to create the relationship between the Monster and Generation or Typing.
View the full customSeed.ts file here on GitHub.
Creating and Seeding the Database
Finally, it's time to seed the database with all the Pokemon data we've scraped. First, we'll need a database to seed into, but Amplication makes that easy. Included by default in the server folder is a file called docker-compose.db.yml with the configuration required to spin up a PostgreSQL instance. When you run the backend locally, it'll be configured to connect to this instance. The only catch is that you'll need to have Docker installed and running. If you still need to set up Docker, check out their getting started guide.
With Docker installed and running, execute the following command.
npm run docker:dbRun this command to initialize the database by creating the necessary schemas and seeding the database using the logic we added to the customSeed.ts file.
npm run db:initQuerying the Pokedex
You've done it! You've found all 1008 Pokemon and added them to your own Pokedex that you made with the help of Amplication. I bet you want to see the fruits of your labor. Let's run the server with the following command.
npm startAfter a minute or so, the server should be up and running at localhost:3000, though that URL won't do much. Instead, you should visit localhost:3000/graphql to be greeted by the GraphQL Playground (if you're interested in testing traditional REST API endpoints, visit localhost:3000/api instead).
Clicking on "DOCS" and "SCHEMA" on the right-hand side will show you everything you can do and see using Pokedex. Below is a sample query you can try yourself and the query variables you need to get something. Put them in and run the query to see what you get.
query monsters($where: MonsterWhereInput) {
monsters(where: $where) {
name
}
}{"where": {"name": {"contains": "Mew"}}}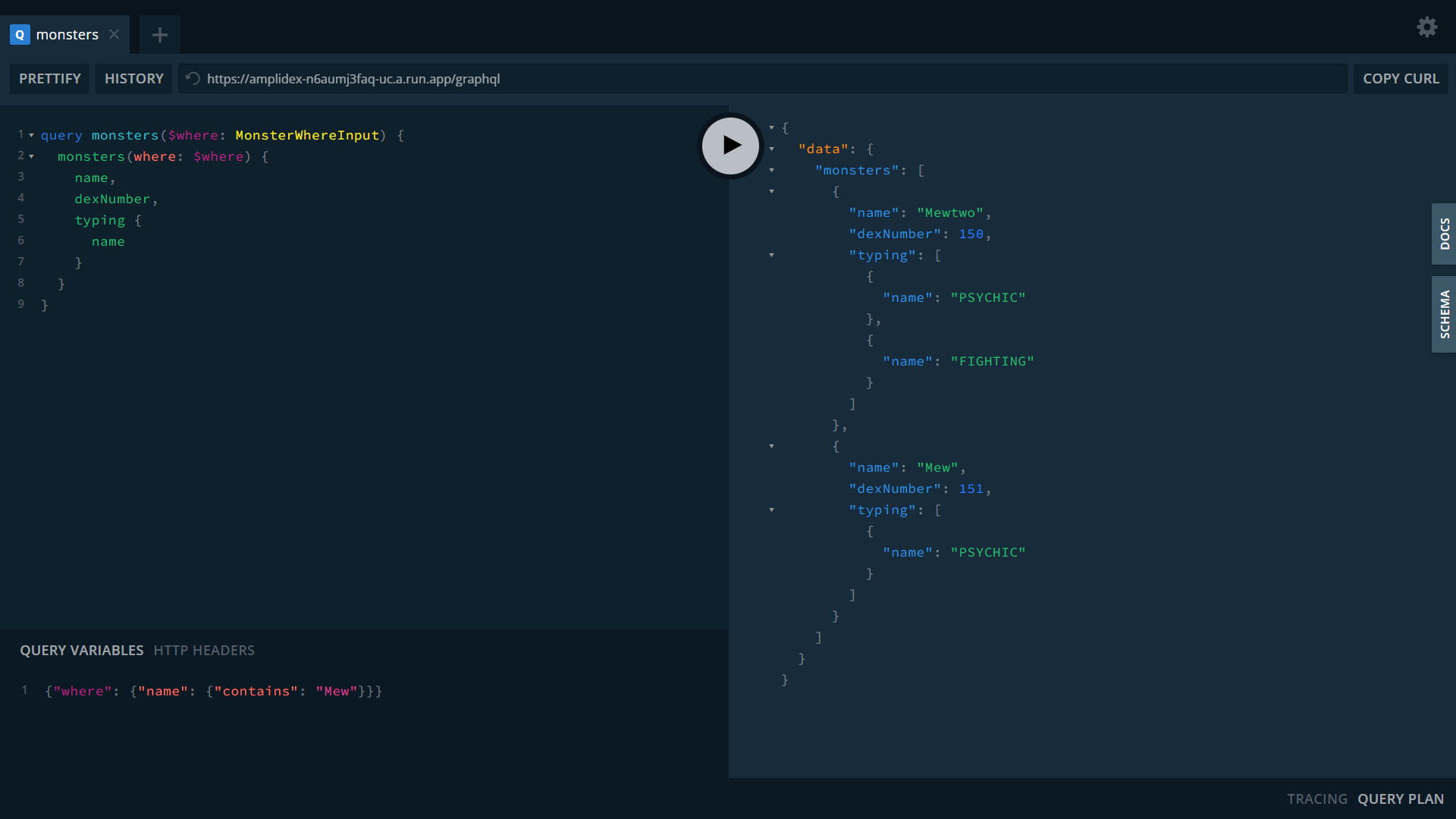
Wrapping Up
With everything we've done up until now, we've created the best Pokedex application with the help of Amplication and Bulbapedia. This may be an exaggeration, but there aren't that many public guides or APIs for something like this. I'm hoping this guide showed you how to:
- Build a backend using Amplication
- Scrape data off of the internet
- How to seed a database
To test the Pokedex GraphQL API, we're hosting a live version here.
Remember to join our developer community on Discord; if you like the project and what we're doing, give us a star on GitHub!
Finally, the source code for this project is available on GitHub, and there's a video guide that you can follow along with the build your Pokedex available on YouTube.