Meta's Llama API: Open Models, Meet Developer Convenience

We keep seeing headlines about new LLMs reaching state-of-the-art performance and dominating benchmarks, which is genuinely incredible progress! But the gap between that and actually getting these powerful models deployed effectively within an application... that's often where the rubber meets the road, and frankly, where things can get pretty messy. Sure, downloading huge model weights is part of it, but creating a reliable, smooth operational workflow around them? That's the harder part.
That's why Meta's announcement at LlamaCon 2025 wasn't just another model drop (though they keep doing that, too, bless their open source ❤️). They unveiled the official Llama API. This is a significant shift. Meta, the champions of open weights you can download and run yourself, is now stepping firmly into the hosted API game.
Why should you, as a developer, care? This move is about bridging that gap between incredibly capable open source models and making them radically easier for us to use in our projects. Think about getting the flexibility and transparency we love about open models combined with the kind of developer experience and convenience we've (sometimes grudgingly) come to expect from the closed-source, API-first players. Plus, Meta made some very interesting decisions with this API, like building in OpenAI compatibility from the get-go. Seriously.
And from where I sit, over here thinking about real-time interactions all day at LiveKit, easier access to faster, cheaper, more capable models? That starts to unlock some really exciting possibilities. Let's dig in.
Meet the Llama Family (Served via API)
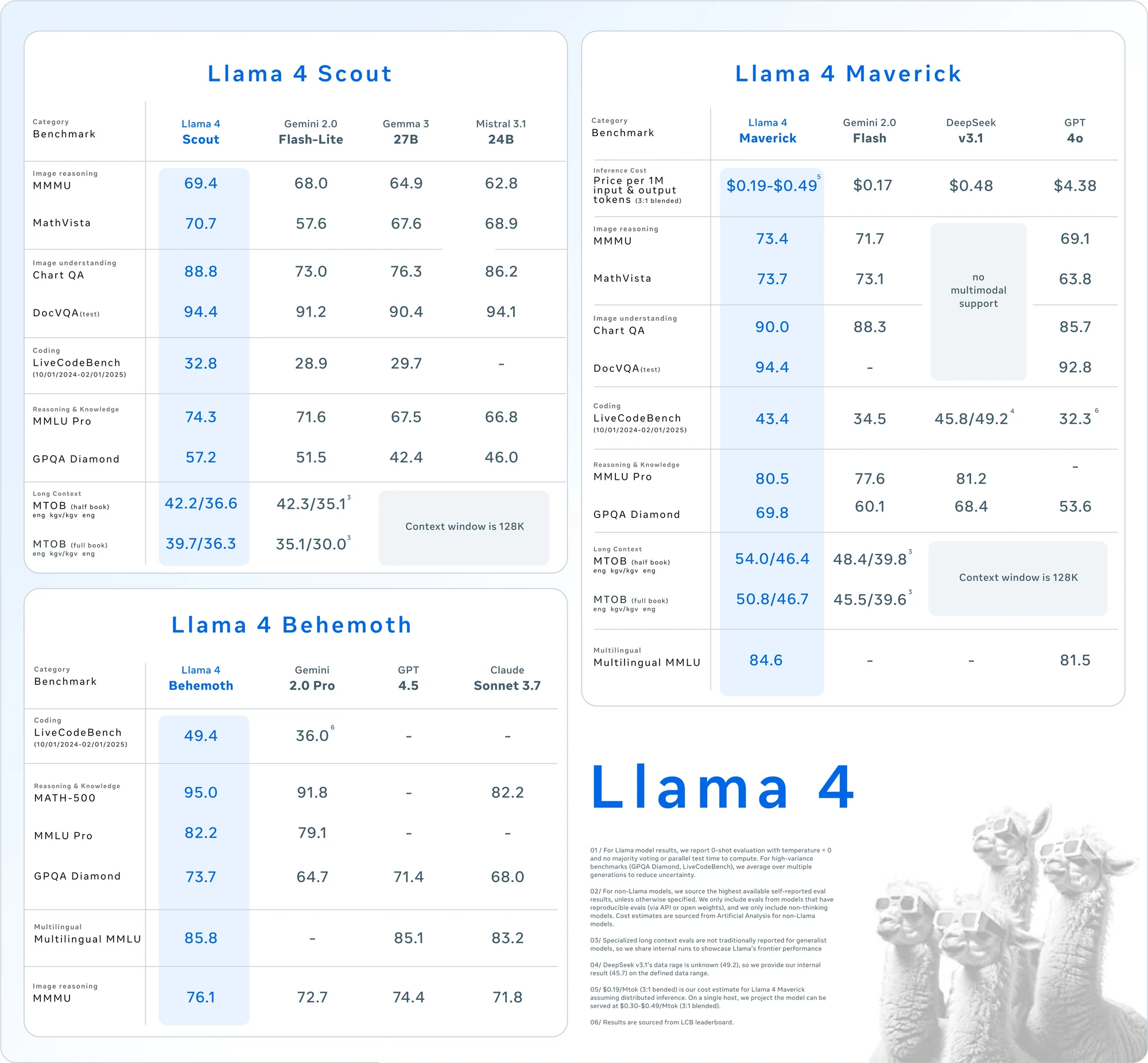
First, this isn't just an API for some legacy model. Meta is directly putting some of its latest and greatest Llama iterations into its hosted service. When it first peaked in preview, it featured the then-new Llama 4 Scout and Maverick models alongside Llama 3.3 8B. Looking at the official docs now, the lineup includes optimized FP8 versions of those Llama 4 models, plus the Llama 3.3 series in both 70B and 8B parameter sizes. (See here)
Let's break down the current herd available via the official API:
- Llama 4 Scout (Llama-4-Scout-17B-16E-Instruct-FP8): This isn't your grandpa's text-only LLM. Scout is natively multimodal, meaning it understands text and images right out of the box. It uses a Mixture-of-Experts (MoE) architecture (17 billion active parameters, 16 'experts') which helps make it efficient. Think more intelligent routing of your requests to specialized parts of the model. The API version uses FP8 precision for efficiency.
- Llama 4 Maverick (Llama-4-Maverick-17B-128E-Instruct-FP8): Scout's sibling, also natively multimodal and running on an MoE architecture, but with way more experts (128 of them!) packed into its 17 billion active parameters. This suggests it might handle more complex or nuanced multimodal tasks. Benchmarks show Maverick punching well above its weight, often outperforming much larger models, especially in image understanding and coding. Again, the API serves an efficient FP8 version.
- Llama 3.3 70B (Llama-3.3-70B-Instruct): The latest iteration of Meta's 70B text-only model line. It boasts improved reasoning, coding chops, multilingual support, and a beefy 128k token context window. Meta positions it as delivering performance comparable to the earlier massive Llama 3.1 405B for text-based tasks, but faster and cheaper.
- Llama 3.3 8B (Llama-3.3-8B-Instruct): The lightweight, speedy sibling to the 70B. It still gets the 128k context window and multilingual capabilities. Still, it is designed for scenarios where you need quick responses and lower resource usage. This was also one of the first models for fine-tuning via the API preview.
Here's a quick look at the models currently listed in the official API docs:
| Model ID | Input Modalities | Output Modalities | Context Length (API) | Key Architecture |
|---|---|---|---|---|
| Llama-4-Scout-17B-16E-Instruct-FP8 | Text, image | Text | 128k | MoE (16 Experts) |
| Llama-4-Maverick-17B-128E-Instruct-FP8 | Text, image | Text | 128k | MoE (128 Experts) |
| Llama-3.3-70B-Instruct | Text | Text | 128k | Transformer |
| Llama-3.3-8B-Instruct | Text | Text | 128k | Transformer |
What's really interesting here isn't just the specs but the strategy. Meta isn't just incrementally improving text generation. They're adding fundamental new capabilities like native multimodality and architectural innovations like MoE that directly target limitations of older models and compete feature-for-feature with the big closed-source players like Google's Gemini and OpenAI's GPT-4 series. Offering these advanced models through an easy-to-use API signals Meta wants developers to have frictionless access to their cutting-edge, not just the older stuff.
The increased context windows across the board (up to 128k standard in the API, a massive leap from Llama 2/3's initial 8k) also unlock more sophisticated applications, from deeper conversations to analyzing larger documents.
The Developer Experience: Less Yak Shaving, More Building
Okay, powerful models are cool. But how easy is it to use them via this new API? This is where Meta has seriously considered reducing friction for developers.
We're talking easy, one-click API key generation and interactive "playgrounds" to quickly test prompts and models. These days, this is standard fare for APIs, but nailing these basics is crucial for getting developers up and running quickly.
As you'd hope, they've rolled out official SDKs for Python and TypeScript. Installation looks super simple (for Python, it's just pip install llama-api-client). The SDK examples lay out ways to use it for chat completion. Plus, you get support for async and streaming responses, which is great.
Now, pay attention, because this next part is the real game-changer and tells you a lot about Meta's thinking: it works with the OpenAI API! Yep, you heard right. They've actually included a dedicated compatibility endpoint at https://api.llama.com/compat/v1/.
What does this mean? You can take your existing code that uses the official OpenAI client libraries, point it to Meta's base URL, and swap in your Llama API key. It should just work for core functionalities like listing models, chat completions (sync and streaming), and even image understanding with Llama 4. Meta explicitly provides examples showing how to do this. This is a massive olive branch for developers already invested in the OpenAI ecosystem. It dramatically lowers the barrier to trying out or switching to Llama. Meta removes the "but I'd have to rewrite my integration" excuse. It's a genius, pragmatic move acknowledging OpenAI's current de facto standard status while leveraging Llama's strengths (like cost and openness) as a compelling reason to make that tiny configuration change.
The API preview wasn't just for running inferences; it also packed tools for fine-tuning and evaluating models. They first showed this off with the Llama 3.3 8B model, letting developers build custom versions right there in the hosted API. This means you could tailor models to your specific needs without wrestling with complex training setups. It really signals that Meta gets that serious AI work often needs more than just a one-size-fits-all model – it needs specialization. Putting these tools in the API turns it from a basic inference point into a much more complete development platform.
Open Arms vs. Walled Gardens: Llama's Place in the AI Bazaar
Meta's entire philosophy with Llama has been centered around openness. They release the model weights, allowing anyone (with the right hardware and expertise) to run, modify, and build upon them. The Llama API fits into this by providing an easier access point to these open models, but it doesn't lock you in. Meta explicitly states that models fine-tuned via the API are yours to take and host elsewhere if you want. This is in contrast to the proprietary API-only approach of competitors like OpenAI, Anthropic, and Google, where the models remain firmly within their walled gardens.
And let's be clear: these open models aren't just "good for open source," they are competitive on performance. Llama 3 models showed significant improvements over Llama 2. They outperformed other open models of similar size on various benchmarks like MMLU, HumanEval, and GSM-8K. The larger Llama 3.1 405B was positioned as rivaling top closed-source models. The newer Llama 4 models, like Maverick, are showing impressive results, even surpassing GPT-4o and Gemini 2 in areas like image understanding (ChartQA, DocVQA) and long-context tasks, according to some benchmarks.
But where Llama really throws down the gauntlet is cost. While Meta hasn't published official pricing for their own hosted API preview (it was mentioned as a free limited preview initially), the pricing from ecosystem partners who offer Llama models via API sets a clear and dramatic precedent. Meta themselves have highlighted affordability as a key benefit, and external analyses confirm Llama often offers some of the lowest costs per token in the industry.
Safety in the Open: Enter Purple Llama
With great power comes great responsibility, right? Meta isn't just tossing powerful models over the wall and hoping for the best. Along with the models and the API, they've invested significantly in building and openly sharing tools for trust and safety under the Purple Llama project umbrella.
The name comes from cybersecurity's "purple teaming," which combines offensive (red team) and defensive (blue team) approaches to finding and fixing vulnerabilities. Purple Llama aims to bring this collaborative, proactive security mindset to generative AI.
Key components include:
- Llama Guard: A family of models (like Llama Guard 3 and 4) specifically designed for content moderation. These can filter both the inputs sent to your main Llama model and the outputs it generates, checking for harmful, unethical, or policy-violating content based on taxonomies like the MLCommons standard. Llama Guard models are available via the API, supporting multiple languages and image reasoning (in Guard 4).
- CyberSec Eval: They've put together a set of benchmarks and tools to check if an LLM is likely to churn out insecure code or help someone with cyber mischief. This is super useful for developers because it lets them measure and lower the cybersecurity risks of using LLMs, especially when those models write code.
- Prompt Guard: A tool focused on catching and blocking prompt injection attacks and jailbreaking. These are the kinds of bad inputs folks use specifically to try and bypass a model's built-in safety controls.
Why does any of this matter? Well, it's a strong sign that Meta is taking the safety concerns around AI models seriously. What's crucial is that they're putting these tools out there openly (with flexible licenses), letting everyone in the community use them, poke around, improve them, and help standardize safety practices. This open safety strategy is a good move, positioning Meta not just as a developer of powerful open AI but as a champion for responsible development.
Conclusion: Let the Llamas Loose
My final thoughts on the Llama API? It's clear this is more than just Meta playing catch-up in the API world. It feels like a deliberate step designed to make their strong open source models much simpler for developers to adopt and work with. It brings together the ease of using a hosted API with all the good stuff people already love about Llama: its performance, affordability, and open nature.
Meta's push with the API, the raw performance/cost advantages of the models, and the explicit focus on speed through partnerships like Cerebras and Groq make a strong argument for the momentum behind open(ly accessible) AI. And from a real-time perspective? The possibilities got a lot more interesting and, crucially, affordable.
Is it worth experimenting with the Llama API? Absolutely. Head over to the Llama Developer Portal, check out the models and SDKs, get on the waitlist if the preview is still limited, and see how it slots into your stack. I'd love to hear what you build with it!